Queries on Multidimensional Data Enriched with Geographic Information
Jose Samos (jsamos@ugr.es)
2020-09-15 (updated 2023-11-10)
Source:vignettes/geomultistar.Rmd
geomultistar.RmdIntroduction
The multidimensional data model was defined with the aim of supporting data analysis. In multidimensional systems, data is structured in facts and dimensions1.
The star model is widely accepted, it is recommended for use in widely distributed end-user tools. In it we have a table for facts and a table for each dimension. Dimensions provide factual views for easy querying.
The geographical dimension plays a fundamental role in multidimensional systems. In a multidimensional schema, there can be more than one geographic dimension.
These dimensions allow us to associate places of different levels of detail with the factual data. For example, we can record data at the city level but later we may be interested in studying them grouped at the zone or nation level.
It is very interesting to have the possibility of representing the reports obtained from multidimensional systems, using their geographic dimensions, on a map, or performing spatial analysis on them. Thus, the goal of this package is to enrich multidimensional queries with geographic data. In other words, it is not a question of making spatial queries but of generating a spatial layer with the result of the multidimensional queries and that this generation is done automatically, once the configuration of the geographical dimensions has been made.
The rest of this document is structured as follows: First we show
various ways to obtain a multistar object. Afterwards, the
functions that allow us to define multidimensional queries are
presented. The following section shows how to add geographic information
to the model and also how to include it in the results of
multidimensional queries. Then, the document ends with conclusions.
Get a multistar object
To perform multidimensional queries, the multistar class
was defined in this package. A multistar implements star
schemas: it has a table for each dimension and a table for the facts;
however, it can contain multiple fact tables with some dimensions in
common.
Using the functions defined in the rolap
package, starting from a flat table implemented by means of a
tibble, we can generate a star database from which we can
directly obtain a multistar object.
If we already have a star schema, geomultistar package
offers functions to generate a multistar object from the
fact and dimension tables in tibble format.
Get a multistar object from the rolap
package
The rolap package allows us to obtain a multidimensional
database from one or more flat tables.
Using the as_multistar() function of this package, we
obtain an object of class multistar that we can work with
directly using the geomultistar package.
Generate a multistar object
In this case, we are going to suppose that we have tables of facts
and dimensions in tibble format, which we have imported
into R. In particular, we have the tables mrs_fact_age,
mrs_fact_cause, mrs_where,
mrs_when and mrs_who: Two fact tables that
share two of the three dimensions.
Add fact tables
We create an empty object, to which we will add elements. First we have to add a fact table, later we will add dimension tables or other fact tables.
ms <- multistar() |>
add_facts(
fact_name = "mrs_age",
fact_table = mrs_fact_age,
measures = "n_deaths",
nrow_agg = "count"
) For the facts we indicate a name, the table that contains its data and the names of the columns that contain the measures.
We can indicate an aggregation function associated with each measure. This parameter should be defined only if some measure is not additive. In this case it is not necessary.
Finally, we can indicate the name of a field that represents the number of rows grouped in each query: We can indicate the name of an existing column in the table for that purpose, or the name that you want to give to the column to be added if none exists. In this case, the name of a column in the table is assigned.
Next we add another table of facts with characteristics similar to the previous one.
ms <- ms |>
add_facts(
fact_name = "mrs_cause",
fact_table = mrs_fact_cause,
measures = c("pneumonia_and_influenza_deaths", "other_deaths"),
nrow_agg = "nrow_agg"
)In this case, the column that contains the number of grouped rows precisely has the name that is assigned by default.
Add dimension tables
Once we have at least one fact table, we can add dimension tables.
ms <- ms |>
add_dimension(
dimension_name = "where",
dimension_table = mrs_where,
dimension_key = "where_pk",
fact_name = "mrs_age",
fact_key = "where_fk"
)For each dimension we define its name, the table that contains the data, the name of the primary key and, for the table of facts with which we are going to relate it, its name and the name of the corresponding foreign key.
To establish the relationship successfully, it is verified that there
is referential integrity between the tables using the indicated columns.
The columns corresponding to the primary and foreign keys are renamed
and are no longer available for queries. If you want to keep the field
in the dimension, it can be indicated by a parameter, as is shown below
by parameter key_as_data.
ms <- ms |>
add_dimension(
dimension_name = "when",
dimension_table = mrs_when,
dimension_key = "when_pk",
fact_name = "mrs_age",
fact_key = "when_fk",
key_as_data = TRUE
) |>
add_dimension(
dimension_name = "who",
dimension_table = mrs_who,
dimension_key = "who_pk",
fact_name = "mrs_age",
fact_key = "who_fk"
)If a dimension is related to more than one fact table, when it is added, its relationship to only one can be defined. Later, additional relationships can be defined, as we will see next.
Relate dimensions
Once a dimension is included in the multistar object, we
can relate it to other fact tables.
ms <- ms |>
relate_dimension(dimension_name = "where",
fact_name = "mrs_cause",
fact_key = "where_fk") |>
relate_dimension(dimension_name = "when",
fact_name = "mrs_cause",
fact_key = "when_fk")In this case, to specify the dimension we only have to indicate its name.
Additional operations on the multistar object
Through the previous operations, we generate a multistar
object to which we can apply the operations defined for this class. At
this moment we can export it as a flat table, using
multistar_as_flat_table, or define multidimensional
queries, as we will later use dimensional_query.
geomultistar query functions
A query is defined on a multistar object and the result
is another multistar object.
This section presents the functions available to define queries.
dimensional_query()
From a multistar object, an empty
dimensional_query object is created where we can select
fact measures, dimension attributes and filter dimension rows.
Example:
dq <- dimensional_query(ms)
select_fact()
To define the fact table to be consulted, its name is indicated, optionally, a vector of names of selected measures and another of aggregation functions are also indicated. If the name of any measure is not indicated, only the one corresponding to the number of aggregated rows is included, which is always included. If no aggregation function is included, those defined for the measures are considered.
Examples:
dq_1 <- dq |>
select_fact(
name = "mrs_age",
measures = "n_deaths",
agg_functions = "MAX"
)The measure is considered with the indicated aggregation function. In addition, the measure corresponding to the number of grouped records that make up the result is automatically included.
dq_2 <- dq |>
select_fact(name = "mrs_age",
measures = "n_deaths")The measure is considered with the aggregation function defined in the multidimensional scheme.
dq_3 <- dq |>
select_fact(name = "mrs_age")Only the measure corresponding to the number of grouped records is included.
dq_4 <- dq |>
select_fact(name = "mrs_age",
measures = "n_deaths") |>
select_fact(name = "mrs_cause")More than one fact table can be selected in a query.
select_dimension()
To include a dimension in a dimensional_query object, we
have to define its name and a subset of the dimension attributes. If
only the name of the dimension is indicated, it is considered that all
its attributes should be added.
Example:
dq_1 <- dq |>
select_dimension(name = "where",
attributes = c("city", "state"))Only the indicated attributes of the dimension will be included.
dq_2 <- dq |>
select_dimension(name = "where")All attributes of the dimension will be included.
filter_dimension()
Allows us to define selection conditions for dimension rows.
Conditions can be defined on any attribute of the dimension, not only on
attributes selected in the query for the dimension. The selection is
made based on the function dplyr::filter(). Conditions are
defined in exactly the same way as in that function.
Example:
dq <- dq |>
filter_dimension(name = "when", week <= "03") |>
filter_dimension(name = "where", city == "Bridgeport")
run_query()
Once we have selected the facts, dimensions and defined the conditions on the instances, we can execute the query to obtain the result.
Example:
dq <- dimensional_query(ms) |>
select_dimension(name = "where",
attributes = c("division_name", "region_name")) |>
select_dimension(name = "when",
attributes = c("year", "week")) |>
select_fact(name = "mrs_age",
measures = "n_deaths") |>
filter_dimension(name = "when", week <= "03")
ms_2 <- dq |>
run_query()
class(ms_2)
#> [1] "multistar"The result of a query is an object of the multistar
class that meets the defined conditions. Other queries can continue to
be defined on this object.
In this case we transform it into a flat table to more easily show the result.
ft <- ms_2 |>
multistar_as_flat_table()Below are the first rows of the result.
| year | week | division_name | region_name | n_deaths | count |
|---|---|---|---|---|---|
| 1962 | 01 | East North Central | Midwest | 2258 | 75 |
| 1962 | 01 | East South Central | South | 526 | 35 |
| 1962 | 01 | Middle Atlantic | Northeast | 3452 | 86 |
| 1962 | 01 | Mountain | West | 414 | 35 |
| 1962 | 01 | New England | Northeast | 785 | 57 |
| 1962 | 01 | Pacific | West | 1567 | 67 |
Add geographic information
Both the multidimensional data model and multidimensional queries can be enriched with geographic information. This is what we are going to do in this section.
Define geographic dimensions and attributes
To define the dimensions and geographic attributes of a
multistar object, we must define a
geomultistar specialization from it, which allows to store
this information.
We create a geomultistar object from a
multistar one defining the names of the dimensions that
contain geographic information. In the example only one dimension.
gms <-
geomultistar(ms, geodimension = "where")For each attribute of a geographic dimension that we want to use in queries, we can define a vector geographic data layer with which a relationship can be established using one or more attributes of the dimension.
gms <- gms |>
define_geoattribute(
attribute = "city",
from_layer = usa_cities,
by = c("city" = "city", "state" = "state")
) For the city attribute, a relationship is defined with a
vector geographic data layer in sf format
(usa_cities), using the city and
state attributes2 that have the same name in the layer.
Sometimes there may be problems establishing the correspondence between the geographic attributes and the vector layer: Instances may remain unrelated. To detect these situations, we can query the rows that do not have associated geometry using the following function.
empty_city <- gms |>
get_empty_geoinstances(attribute = "city")The result obtained is shown below.
| city | state | geometry |
|---|---|---|
| Unknown | Unknown | GEOMETRYCOLLECTION EMPTY |
In this case, for the unknown cities, their location has not been determined. There may be several because other geographic data of less granularity may be known.
In the same way, the relationship for county with the
corresponding layer (usa_counties) is defined.
gms <- gms |>
define_geoattribute(
attribute = "county",
from_layer = usa_counties,
by = c("county" = "county", "state" = "state")
) We check if they have all been related.
empty_county <- gms |>
get_empty_geoinstances(attribute = "county")And the result obtained is shown below.
| county | state | geometry |
|---|---|---|
| Unknown | Unknown | GEOMETRYCOLLECTION EMPTY |
It also happens for the same instances. In this case we can see that the associated geometry is of a different type.
In the case of state the definition is carried out by
associating the code to the corresponding one in the layer
(usa_states).
gms <- gms |>
define_geoattribute(
attribute = c("state"),
from_layer = usa_states,
by = c("state" = "state")
) Additionally, for an attribute we can generate its layer from the one
associated with another related attribute of the dimension. This is what
has been done below for division.
gms <- gms |>
define_geoattribute(
attribute = "division",
from_attribute = "state"
) In this case, the vector layer is generated from the data available in the layer under consideration. Sometimes this is precisely what is desired. If not, look for a vector layer at that level of detail.
If no attribute name is indicated, this operation is applied to the rest of the attributes of the dimension that do not have an associated vector layer by any of the methods presented, as shown below.
gms <- gms |>
define_geoattribute(from_attribute = "state")With this we have all the attributes of the dimension with an associated layer, defined at its level of granularity3. On the other hand, we can change the layer of any attribute at any time, independently of the rest.
Run queries adding geographic information
Next we define the same query as before but on the data model enriched with geographic information.
gdq <- dimensional_query(gms) |>
select_dimension(name = "where",
attributes = c("division_name", "region_name")) |>
select_dimension(name = "when",
attributes = c("year", "week")) |>
select_fact(name = "mrs_age",
measures = "n_deaths") |>
filter_dimension(name = "when", week <= "03")
gms_2 <- gdq |>
run_query()
class(gms_2)
#> [1] "multistar"If instead of executing the standard query, we execute
run_geoquery() function, we automatically obtain a vector
geographic data layer at the finest possible level of detail, depending
on the definition of the query.
vl_sf <- gdq |>
run_geoquery()
class(vl_sf)
#> [1] "sf" "tbl_df" "tbl" "data.frame"The first rows of the result can be seen below in table form.
| year | week | division_name | region_name | n_deaths | count | geometry |
|---|---|---|---|---|---|---|
| 1962 | 01 | East North Central | Midwest | 2258 | 75 | MULTIPOLYGON (((-84.65 45.8… |
| 1962 | 01 | East South Central | South | 526 | 35 | MULTIPOLYGON (((-88.4 30.37… |
| 1962 | 01 | Middle Atlantic | Northeast | 3452 | 86 | MULTIPOLYGON (((-72.03 41.2… |
| 1962 | 01 | Mountain | West | 414 | 35 | MULTIPOLYGON (((-109.1 41, … |
| 1962 | 01 | New England | Northeast | 785 | 57 | MULTIPOLYGON (((-71.59 41.1… |
| 1962 | 01 | Pacific | West | 1567 | 67 | MULTIPOLYGON (((-156.1 19.7… |
The result is a vector geographic data layer that we can save,
perform spatial analysis or queries on it, or we can see it as a map,
using the functions associated with the sf class.
plot(vl_sf[,"n_deaths"])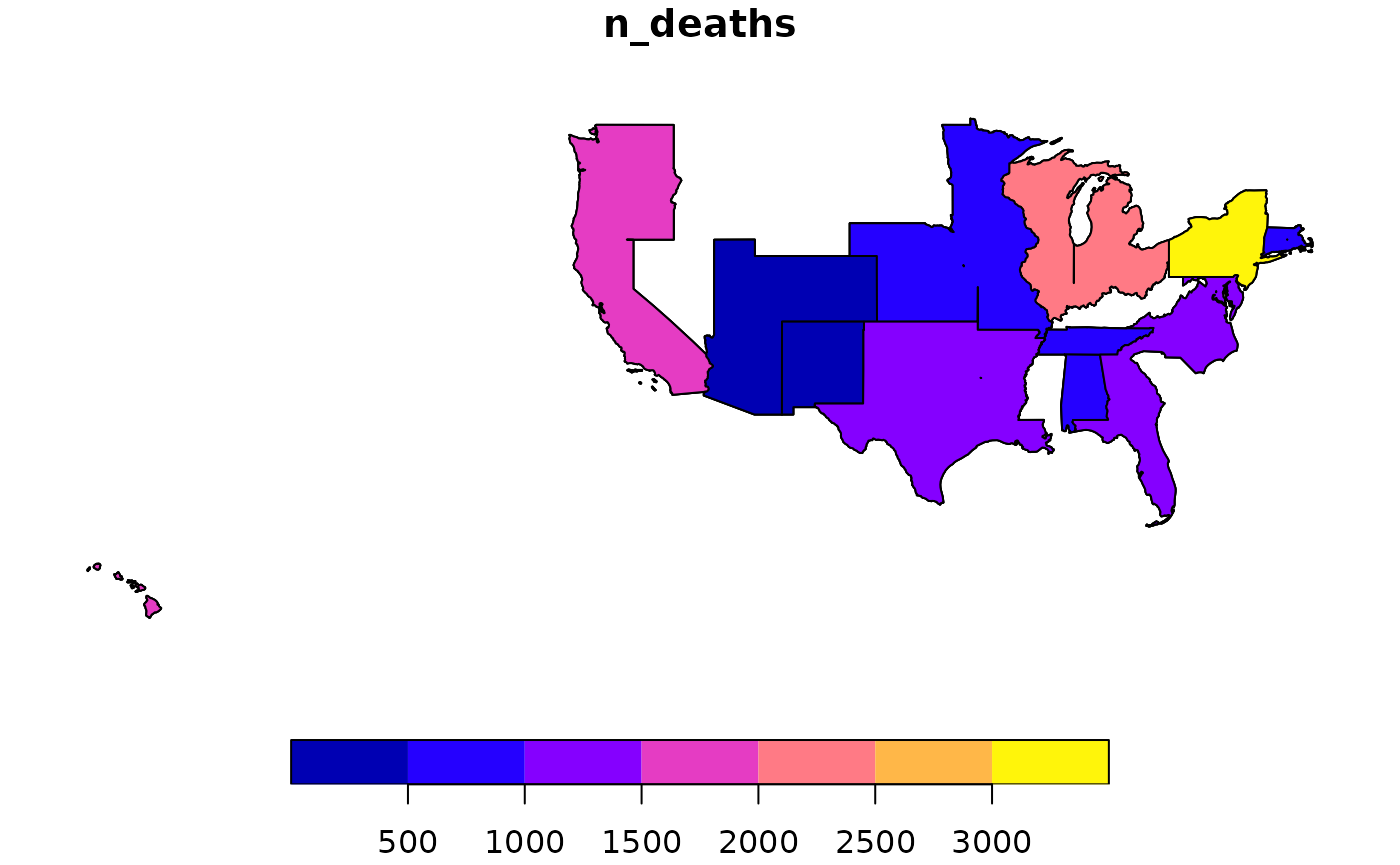
Although we have indicated in the query the attributes
division_name and region_name, as can be seen
in the figure, the result obtained is at the finest granularity level,
in this case at the division_name level.
Only the parts of the divisions made up of states where there is recorded data are shown. If we wanted to show the full extent of each division, we should have explicitly associated a layer at that level.
Get wide tables
In geographic layers, geographic objects usually are not repeated.
The tables are wide: for each object the rest of the attributes are
defined as columns. By means of the parameter wider we can
indicate that we want a result of this type.
vl_sf_w <- gdq |>
run_geoquery(wider = TRUE)The first rows of the result can be seen below in table form.
| fid | year | division_name | region_name | n_deaths_01 | n_deaths_02 | n_deaths_03 | count_01 | count_02 | count_03 | geometry |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1962 | East North Central | Midwest | 2258 | 2289 | 2314 | 75 | 76 | 75 | MULTIPOLYGON (((-84.65 45.8… |
| 2 | 1962 | East South Central | South | 526 | 575 | 650 | 35 | 33 | 32 | MULTIPOLYGON (((-88.4 30.37… |
| 3 | 1962 | Middle Atlantic | Northeast | 3452 | 3426 | 3413 | 86 | 90 | 91 | MULTIPOLYGON (((-72.03 41.2… |
| 4 | 1962 | Mountain | West | 414 | 411 | 472 | 35 | 34 | 35 | MULTIPOLYGON (((-109.1 41, … |
| 5 | 1962 | New England | Northeast | 785 | 785 | 726 | 57 | 61 | 57 | MULTIPOLYGON (((-71.59 41.1… |
| 6 | 1962 | Pacific | West | 1567 | 1823 | 1637 | 67 | 67 | 66 | MULTIPOLYGON (((-156.1 19.7… |
We can see that the attributes that are multivalued for each geographic object have been eliminated from the result table, and new measurement columns have been generated: one for each combination of values of these attributes with the original measurements.
The meaning of the name of the columns of the measurements is part of the result obtained, also in table format, as can be seen below.
| id_variable | measure | week |
|---|---|---|
| n_deaths_01 | n_deaths | 01 |
| n_deaths_02 | n_deaths | 02 |
| n_deaths_03 | n_deaths | 03 |
| count_01 | count | 01 |
| count_02 | count | 02 |
| count_03 | count | 03 |
In this case there was only one variable with a multiplicity greater than one. If there were more variables in this situation, they would be added to this table in the same way.
This data dictionary table and layer structure can be saved in
GeoPackage format using the save_as_geopackage()
function.
filepath <- tempdir()
l <- save_as_geopackage(vl_sf_w, "division", filepath = filepath)
#> Deleting source `/tmp/RtmpOqi0Ty/division.gpkg' failed
#> Writing layer `division' to data source
#> `/tmp/RtmpOqi0Ty/division.gpkg' using driver `GPKG'
#> Writing 9 features with 10 fields and geometry type Unknown (any).
file <- paste0(filepath, "/division.gpkg")
sf::st_layers(file)
#> Driver: GPKG
#> Available layers:
#> layer_name geometry_type features fields crs_name
#> 1 division 9 9 NAD83
#> 2 division_variables NA 6 3 <NA>The GeoPackages thus obtained can be used directly, for example in QGIS.
Conclusions
To generate the multidimensional structure on which to define
queries, we can use the functions of the rolap
package or, if we already have the multidimensional design implemented,
the import functions included in this package.
The geomultistar package allows generating vector
geographic data layers in sf format as a result of
multidimensional queries. To do this, all we need is to associate vector
geographic data layers with some of the attributes of the geographic
dimensions, so that the layers associated with the rest of the
attributes can be obtained automatically. Queries do not present any
additional difficulties due to the fact of returning geographic
data.
The data obtained can be processed with the sf package
to define spatial queries or analysis, be presented in maps or saved as
a file to be used by a GIS (Geographical Information System)
tool.